☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Técnicas Supervisadas Aproximación no paramétrica
sss
Ideas que valen $us 10,000
Document
Diapositiva 1
Tema 3:
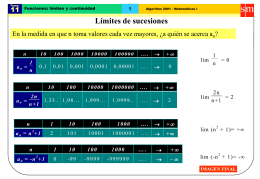
Límite de una sucesión
Jueves 22 de febrero
Diapositiva 1
Continuidad deFunciones
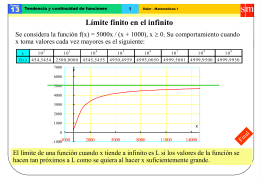
límite al infinito
Tema 11. Funciones: Límites y continuidad
File
Ingeniería en Sistemas de Información
Tendencia y continuidad
RECLUTAMIENTO DE PERSONAL - ITCh DEPI
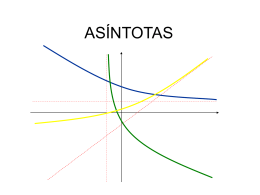
Asíntotas
limites y continuidad
Reconocimiento de Caras con información local
Semántica Léxica
Historia de la Computación - Departamento de Ingeniería de
El Nro que Ud. necesita para crecer