☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ingeniería
09_Diseno_Experimento
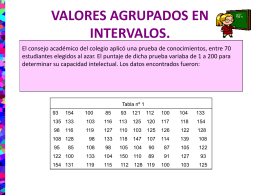
VALORES AGRUPADOS EN INTERVALOS
números reales
ritmo-armonia-melodia
Un intervalo de 95% de confianza para la diferencia de las medias
CADENAS PRODUCTIVAS
Capitulo 2: Distribución de frecuencias unidimensionales
analisis factorial de la varianza (kerlinger y lee 14
Document
Intervalos de Confianza
File - albeiro vergara urango
Gráficos de datos
s rales 8
Técnicas de conteo
Diapositiva 1
Diapositiva 1
Diseños factoriales_1
presentación en Power Point
Geoestadística Multivariada