☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Condiciones de Kuhn
Diapositiva 1 - CEIS Maristas
combinaciones lineales convexas
No Slide Title
Sistema de valores y vectores propios de una matriz
Selección sexual
Negociación y Manejo de Conflictos
Cantidad de Información de Fisher y propiedades de
distribucion-f-de-fisher
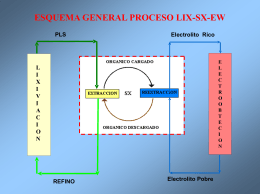
Proceso LIX-SX-EW
Diapositiva 1
Prevención y control del error
Presión
BUENAS PRÁCTICAS DE LABORATORIO
Representación gráfica de vectores
Carbenos y Carbinos
análisis discriminante
Notificación previa Ley de Bioterrorismo FDA-USA
Avances, retos y perspectivas del Programa de Cultura de
Diapositiva 1 - CEIS Maristas
Análisis Discriminante
Presentacion-PCA