☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Análisis Discriminante
análisis discriminante
Condiciones de Kuhn
Investigación Secundaria y Estadísticas Oficiales
Teoria de Probabilidades
Folie 1 - LEMA PROJECT
Estrategia de la Copia de seguridad
resumen1 - WordPress.com
Conceptos básicos de probabilidad
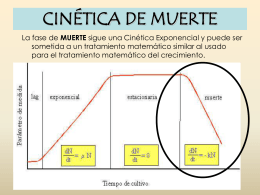
Cinética de Muerte
3_termodinámica_soluciones