☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Deportes
Estadística… ¿Para que nos sirve…?
XII Reunión de Economía Mundial, Santiago de Compostela 26
Tasas, Razones Y Proporciones
Tipos de artículos en una publicación científica
Gráficos de datos
Diapositiva 1 - bornthiswayxD
Taller Periódicos murales
Análisis Técnico
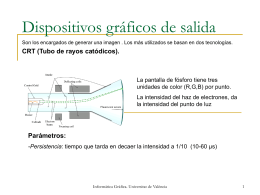
Dispositivos gráficos de salida
Quién construye sitios web
TÉCNICAS DE TRADING
2009-05-26 Preservacion Recreativas
Métodos gráficos de control - Universidad del Valle de Guatemala
Lección 4
CONTROL ESTADÍSTICO DE LA PRODUCCIÓN CARTAS DE
Escribir con este tamaño de letra títulos
Cuadernillo Compañero - Guias Mayores Mexico IASD
Lucas Refundini - Escuela de Ingeniería Eléctrica
medidas-de-posicion
estimación del tamaño de la muestra
Título de una línea o de dos líneas, separado del logotipo
Intervención Breve PPT
TUTORIAL SPSS