☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
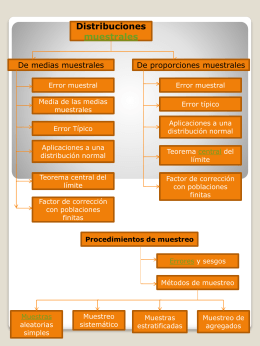
No category
H 1
Diapositiva 1 - Escuela Virtual para Padres y Madres
García García JJ. Normalidad. (Presentación en PPT)
Tests no paramétricos
Diapositiva 1
fundamentos de los conceptos de normalidad
Investigación Secundaria y Estadísticas Oficiales
Presentación de Pruebas
Conceptos básicos de probabilidad
Muestras y estadísticos
Normalidad/anormalidad
error muestral - WilliamTeneda
resumen1 - WordPress.com
Herramientas de diagnóstico y resolución de problemas de Windows
Presentación de PowerPoint - AUTO-401
Desarrollo histórico del mov sobre la CALIDAD
Distribucion normal
Continuidad del Negocio
CONCENTRACION DE LAS SOLUCIONES II
4. Distribuciones de probabilidad
Componentes Principales
PROBABILIDAD