☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slides
Bienvenido - Nexxt Learning Center
¿Qué Leer?
Gestión del Conocimiento en redes interinstitucionales
Aprendizaje activo - Facultad de Ingeniería
Estrategias de aprendizaje en línea: Un modelo - CAA
desarrollo de actividades de contabilidad adaptadas a los distintos
Gestión del Conocimiento en Organizaciones - DPEC
IMARK & E – Learning: Cambio en el Paradigma de
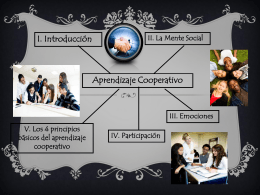
Aprendizaje Cooperativo
Diapositiva 1