☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Analisis cluster.7
SECTORES ECONÓMICOS
Presentación de PowerPoint
PRESENTACION: presentacionbeowulf
Presentación Industria de Salmonicultura - Metalurgia
Ramas de Cargo o Puesto
Nivel 1
Sector Software en la Argentina
DISEÑO FÍSICO relacional
Cisco Presentation Guide
Escalogramas multidimensionales
Encuentro y Capacitación sobre PAD (Power Point )
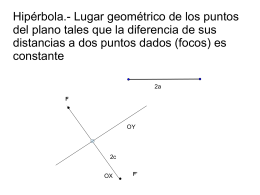
Hipérbola.- Lugar geométrico de los puntos del plano tales que la
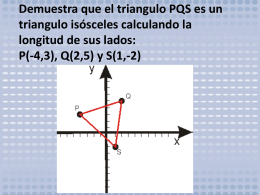
Demuestra que el triangulo PQS es un triangulo isósceles
Regla de signos