☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Presentación de PowerPoint
Recuperación de Información Lematización
PRESENTACION: presentacionbeowulf
Clusters2009
Elección de un diseño de investigación.
Los mandatos de la clase
Analisis cluster.7
Diapositiva 1 - Universidad Pablo de Olavide, de Sevilla
Frases Utiles para la clase de Español
MORFOLOGÍA: La derivación
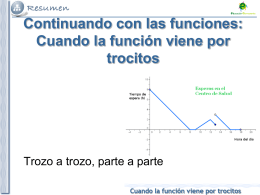
Resumen
SOBRE LOS CARTELES
Módulo III Complementariedad de dos enfoques
Los límites de la huelga: el respeto de los servicios esenciales
Resumen
5 - genoma . unsam . edu . ar
Donuts, Scratches and Blanks: Robust Model
Presentación Industria de Salmonicultura - Metalurgia
Clustering - Fernando Berzal
Clusters - Aula Virtual - Universitat de València