☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slide 1
Análisis de Correlación y de Regresión lineal simple
Document
METODOLOGIA DE LA INVESTIGACION
Diapositiva 1
A.4 REGRESION LINEAL SIMPLE
Normalidad, Variabilidad y estimación del Modelo
REGRESION LINEAL SIMPLE
Técnicas de Proyección del mercado
Tema24-Regresion - conf
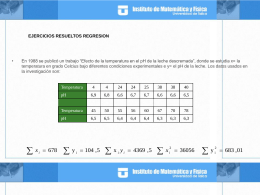
Ejercicios Resueltos Regresion
Pronósticos, Series de Tiempo y Regresión
Precisión de las medidas y tratamiento de resultados
Diapositiva 1
Bioestadística - Apuntes DUOC / FrontPage
Bioestadística