☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Genoma Humano - Blog de Química Biológica Patológica
Genes e ingeniería genética
Lo último en Genética: ¿Cómo lo afecta a Usted?
ALCANCES DEL PROYECTO GENOMA HUMANO
Movilización del elemento P
Introducción a la Bioinformática
Cultivos Transgénicos: ¿Frankenfood vs. Robin Food?
Terapia génica por Nava Gómez Channtal Esther (power
sólo quedan 5 semanas ingenieria genetica
Tema 15: Herencia no mendeliana y elementos genéticos móviles
MODELO OPERON
Clase sobre predicción de genes
KARP_7a_c10_NATURALEZA_GENES_GENOMA
SÓLO QUEDAN 5 SEMANAS
una amiga que está estudiando biología en Una Universidad
examen diagnóstico - Instituto de Investigaciones Filosóficas
Clase 3 - TP Resistencia a enfermedades Mejoramiento de la res
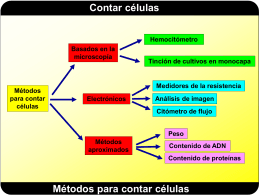
Contar células Funcionamiento del contador de (2
Tema 3. Evolución
Construcción de árboles filogenéticos