☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
para ver las diapositivas
TENDENCIAS DURANTE LOS OCHENTA
F de Fisher - WordPress.com
Análisis de varianza
¿Cómo se logra que se acepten los trabajos de investigación?
Investigación pura - mercadotecniaycomunicacioncorporativa
Estadística y Probabilidad I
SUPUESTOS DEL ANALISIS DE VARIANZA
presentacion Elton Mayo nuevo
Demostración de cultivos de invierno
Aviación Experimental
Document
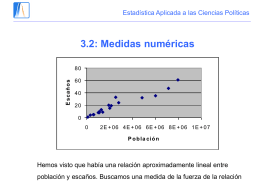
Diapositiva 1
Diapositiva 1