☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Diseño de la Muestra EXPO
Ingeniería del trabajo
Diapositiva 1
Modulación de pulsos
estimación del tamaño de la muestra
Descarga
Población y muestra
Métodos de muestreo
TEORIA DE LA PERSONALIDAD
expocicion - WordPress.com
Muestra y población
Descarga
Población y muestra
Capítulo 11. Muestreo: diseño y procedimiento
Document
Diseño de Experimentos curso 11
6. MUESTREO ESTRATIFICADO
Slide 1
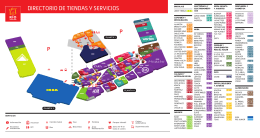
AF_ guiatiendas2