☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Evaluación
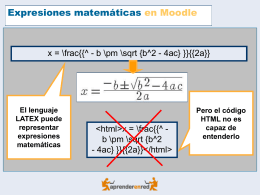
PPT - WIRIS docs
no han demostrado riesgo
El viaje
Herramientas de Google - E
Sección 1: Requisitos y capacidad para convertirse en un proveedor
RANKING DE NOTAS - Colegio Dario Salas
Descargar documento - MBA & Educación Ejecutiva
En los grandes lugares para trabajar se asegura la equidad de género
Usar los filtros para insertar expresiones