☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
ESTIMACIÓN DE COEFICIENTES DE MÁXIMA VEROSIMILITUD
Estrategia de la Copia de seguridad
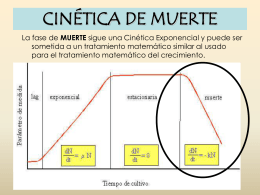
Cinética de Muerte
3_termodinámica_soluciones
Logaritmo y exponencial
Capacidad de un canal
Estructura y Evolucion de las Estrellas
Presentación de PowerPoint
distribución de valor extremo
Restauracion de BD
Biometria_Forestal_-_Practico_14_