☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Cognate or False Friend? Ask the Web!
Unsupervised Extraction of False Friends from
A Knowledge-Rich Approach to Measuring the Similarity
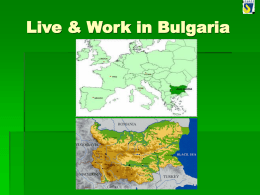
Live & Work in Bulgaria - Nodarbinātības valsts aģentūra
Document
new logo template
Document
www.euroed.ro - echa network
PPT2
Question Answering at TREC-10
Hello
Researching Business Needs and University interactions in
Document