☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Intelligent Information Retrieval and Web Search
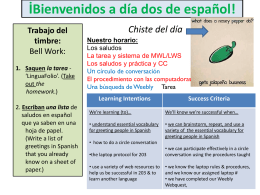
İBienvenidos a día dos de español! - El Sitio de Srta. Berndt
Early Internet
Intelligent Information Retrieval and Web Search
Slide 1
Building the Business Case for Metadata in the Enterprise
6. Hypothesis Testing and the Comparison of 2 or More
Angles & Radian Measure - Georgia Highlands College
teacherstefaniagd4.jimdo.com
An introduction to World Languages at Herricks
Document
Skill up lesson - What`s the conclusion - Student sheets (PPT
Design Patterns:
Marzano’s High Leverage Strategies
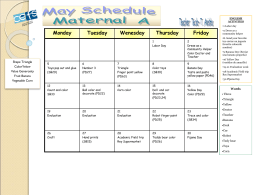
CEFS-MAY-SCHEDULE
STICH Viability Hypothesis
Chapter 1.3