☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
6. Hypothesis Testing and the Comparison of 2 or More
AP Statistics – Chapter 9 Notes
Introduction to Hypothesis Testing
False Discovery Rate, Concept and R Implementation
H. Igor Ansoff
Introduction to Language: Animals and Human Language
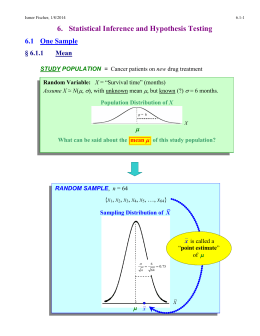
6. Statistical Inference and Hypothesis Testing
Software Project Management
Chapter 1 Chemistry: The Study of Matter
Business Statistics for Managerial Decision
Three suggestions for Usable Formal Methods
Statistical vs Clinical Significance
Transaction Processing Systems (TPS)
Amazon S3 – An SOA
Document
Much Ado About Nothing (NULL)
Skill up lesson - What`s the conclusion - Student sheets (PPT
CIS732-Lecture-02-20080125 - Kansas State University
Document
PowerPoint Presentation - ANOVA: Analysis of Variation
Intelligent Information Retrieval and Web Search
Languages in the U.S.
E-business and The Future