☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slide 1
El faro del Pacífico entra en erupcion
Diapositiva 1
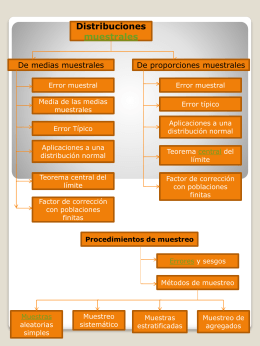
Teorema del límite central
Estimacion de la diferencia de medias poblacionales (Formulas)
Capitulo 8: Introducción a modelos de series temporales
SPAN 3160
La Ropa
Muestra y población
error muestral - WilliamTeneda