☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Slide 1
¿Qué figura elegí y por que?
Ejemplo - WordPress.com
No Slide Title
Document
Diapositiva 1
ANALISIS DE ALTERNATIVAS
El proceso de escritura - Utah Spanish Dual Immersion
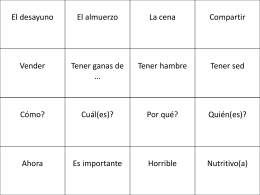
La Comida
Unidad 6 - claves
Diapositiva 1 - Revistaliterart.plural
Inteligencia Artificial
Aplicaciones
Generación
n-gram
morfotáctica
Generación
Document
Estado 1
gato (n)
A, B
PÖTTINGER HIT