☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Document
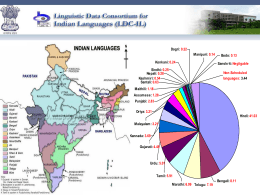
INDIA - UNT College of Arts and Sciences
Faces of Indian Women - Sam Houston State University
Slide 1
Indian Education Act
Document
Chapter 18: Conquest and Survival of the West, 1860
First Nation Governance
Document
Financial Analysis & Tools For Product Management
A New Method of Weighting Query Terms for Ad
India - truth alone triumphs
India`s Engagements in Africa
Overview of Verbal Behavior
Judging a Person's Characteristics Using Astrology
UBS Template (reduced)