☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
1. Desarrollo de Programas iterativos usando invariante
Desarrollo del Nodo Chile dentro del Campus Virtual en
Redes de Flujo
Comunicaciones convergentes: Ingeniería de tráfico
Pensamiento estratégico VB
Subtle Waves Template
Diapositiva 1
Document
INVESTIGACIÓN DE OPERACIONES
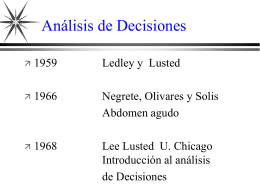
Analisis de Decisiones - Facultad de Medicina UNAM
Listas Ligadas Simples