☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Error Control Coding, Cancer Development and Statistical
History and Impact of Sci. Vis.
Writing science in plain English
Genetic Genealogy, History and Prehistory, and DNA
GENETINC ENGINEERING
Document
Introduction to Organic Chemistry 2 ed William H. Brown
Document
Evolution
DNA-dblehelix - Site GENEMOL 2013
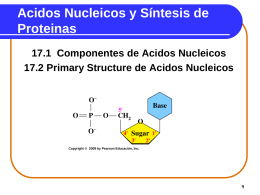
Nucleic Acids
Three main topics for this Intro lecture:
Document
PSYCHOLOGY (9th Edition) David G. Myers
Programming Languages - College of DuPage
Document
Fault Tolerance in an Event Rule Framework for Distributed
Slide 1