☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Diapositiva 1 - ALT.NET Hispano
Mi Familia - deemprojects
BigTable - Asteriscus.com
Drupal y mongoDB
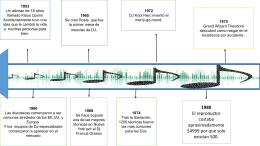
Linea del tiempo Djs
Ventas Externas País
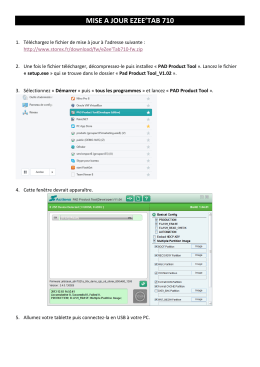
MISE A JOUR EZEE`TAB 710
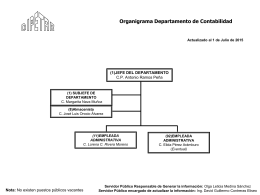
Organigrama Departamento de Administración
DELITO CONTRA LA VIDA
ppt_ig_10_julio_2014
La biblioteca como epicentro académico universitario
DX Lab - Colegio Médico de Honduras
Mi Niñez
Descarga