☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Probabilidad y estadística - CIAM
oooooooooooooo`pppppppppaaaaaaaaaaaaa
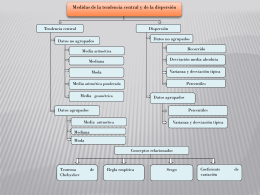
Medidas de Tendencia Central
Tratamiento de datos y azar
ESTADISTICA
Medidas de tendencia Central
Descarga - Profe Marcelo.com
Antecedentes De la Investigación
Diapositiva 1 - WilliamTeneda
unidad iii - WordPress.com