☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Búsqueda heurística
pptx
MÉTODO HEURÍSTICO
Búsqueda Informada
LOS ALGORITMOS INFORMADOS DE BUSQUEDA
pptx
EjemplosCiclos
Glosario de Carlos von der Becke - Cap 4
Biblioteca estándar de templates de C++ Standard Template Libra
Divide & Conquer: problema del par más cercano
Cap4
Intensidad
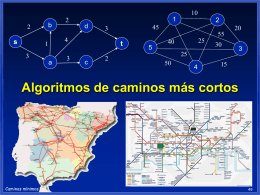
Algoritmo Dijkstra
Arreglos y listas enlazadas
Árbol B
Reconocimiento oficial Power 2010
Clase05Mason - departamento de procesamiento de señales
Funciones del Lenguaje
Listas enlazadas
Arboles (Trees)
Programación en Redes
Listas enlazadas c++
Servicios de Reloj - Departamento de Sistemas e Informática