☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Skip_List - Universidad Nacional de Colombia
Felicidades Virgen de Guadalupe - seed394internshiplampman-g
Diapositiva 1
Sistema de Pagas e Incentivos
Frida Kahlo: A Protrait of an Artist
La Tortuga Asesino
Document
Estrategia de la Copia de seguridad
Diego Rivera
Termodinámica de soluciones
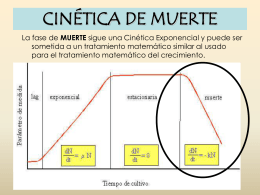
Cinética de Muerte