☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Redes Neurais Artificial
Redes Neurais Artificial
Pesos e Medidas
Introdução às Redes Neurais
Células de Carga: A célula de carga é um dispositivo usado
Métodos de medição - antropometria
Click here to get the file
predição de anomalias gravimetricas de ar
Capítulo 16 A Consciência Regulada
O que é inteligência Artificial?
Momentos e Centro de Gravidade
Plasticidade cerebral - José Salomão Schwartzman
O EXPERIMENTO (A Formação de Ciência – Alan
3ª SEMANA – FORMAÇÃO DO EMBRIÃO
Antisocial Behaviour – Bullying Family Violence and Young
Mapas Auto-Organizáveis de Kohonen
Monitores e Fatores Humanos
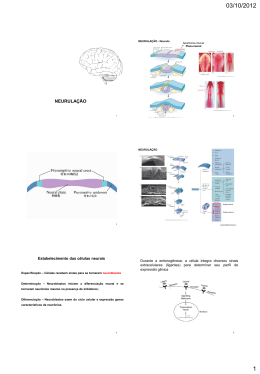
neurulação
Aulas 12, 13 e 14 - Vias
descargue el folleto informativo
Sistema especialista
Melina Swain - Paulo Roberto Margotto
Fisiologia Sensorial - Espaço de Erika Liz