☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Building Workload Characterization Tools with Valgrind
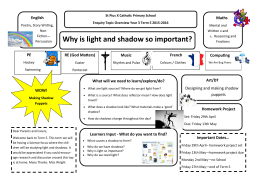
Why is light and shadow so important?
Language Arts - Brooklyn High School
The 20th Century
What is the shadow price for constraint 1?
Governance as a Weapon: Advising the
CS271 ASSEMBLY LANGUAGE PROGRAMMING - UW-W
Shadows - CIS 565
Pentium and PowerPC Data Types
Satyamev Jayate’ Presents
Document
Chapter 2 Data Communication Concepts
Introduction - George Mason University
Shadow Mapping with Today’s OpenGL Hardware
Introduction to computers
Size and Development of Tax Evasion in 38 OECD coun
No Slide Title
ENGR2216 FORTRAN PROGRAMMING FOR ENGINEERS
8 September - Computer Science
Instruction Sets - George Mason University
Shadow Teaching Scheme for Children with Autism and Attention