☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Introduccion a las bases de Datos
Consejo Social de la UNLP
Introduccion a las bases de Datos - III-LIDI
Ama, cree y sonríe
Introduccion a las bases de Datos
Introduccion a las bases de Datos - III-LIDI
Diapositiva 1
Diapositiva 1
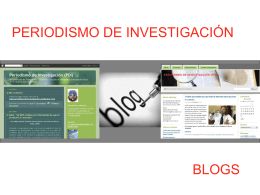
PERIODISMO DE INVESTIGACIÓN Y BLOGS
Condición de la Infraestructura Urbana en Santo Domingo ¿Un
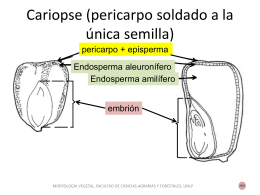
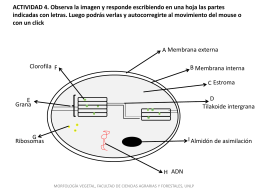
Diapositiva 1 - Morfología Vegetal
En el Hotel
Introduccion a las bases de Datos
ENUMERAR
Introduccion a las bases de Datos