☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ingeniería
AC20101-c21-18nov2010
Slide 1
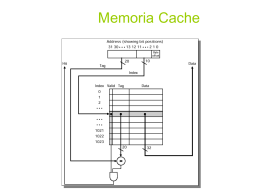
Memorias
Rebeca y Miss Lunatic
Guía Metodológica para el Análisis de las Cadena Product.
¿Cuál es la misión de los PADRES?
Perifericos Entrada y Salida
Encuentros de Poder II - W. Madera
ESTRUCTURA JURIDICA DE LA PEQUEÑA Y
Programación de Computadores IWI-131
Descubrir la voz de Dios en las vocs
La Guerra Fría 1945-1991
Pseudocodigo
Heap