☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
The Nature of Learning
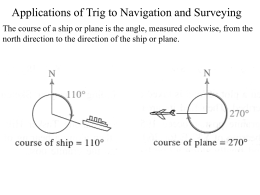
Applications of Trig to Navigation and Surveying
Principles of Taxation - Flushing Community Schools
Compass Test Registration Instructions
How to use a compass
Slide 1
Small Body Navigation at JPL - California Institute of Technology
points of the compass
Since 1983, the ACT Compass program has been instrumental in
6 things beginning with R
compass - Bluefield High School
Unit 2, Story - Sound City Reading
Four Simple Steps to Healthier Bees By Michael Bush
AC*State Administrative Standards Review
Διαφάνεια 1 - Carnegie Endowment for
Compass Surveying :-
compass - Bluefield High School
Canaries in a Coal Mine - Wayne State University
Compass surveying
Presentation - NIA - Elizabeth City State University
“COMPASS CRAZY” #2 - Girl Scouts of Greater Atlanta
Link-Belt™ ES Series™ Idler Rolls
Link-Belt® ES Series™ Idler Rolls