☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
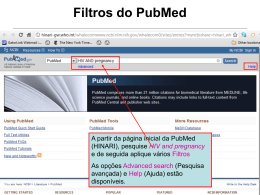
No category
Bancos de dados Biológicos
PPT - Instituto de Computação
Marketing de relacionamento
Slides completos de Fred sobre Ontologia
Slide 1
NCBI Literature Databases
Bancos de Dados Biológicos I
Slide 1
Slide 1