☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Bancos de Dados Biológicos I
Progeria - trabalho I
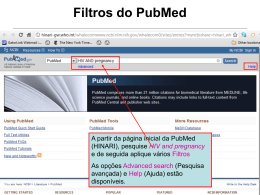
NCBI Literature Databases
HERANÇA E SEXO
Bancos de dados Biológicos
Document
Slide 1
SDL - Specification and Description Language
Slide 1
Elaboração de Relatórios e Resumos Científicos.