☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
High contrast colours will help audiences to read text
T-Tab Print and Post
LSA.303 Introduction to Computational Linguistics
LING 180 Intro to Computer Speech and Language …
LING 180 Intro to Computer Speech and Language Processing
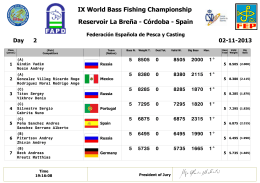
IX World Bass Fishing Championship Reservoir La Breña
Profile
STATUS AND CORPUS PLANNING: ADDRESSING …
CPSC Computational Linguistics
PPT2
Corpora and Statistical Methods Lecture 12
Chapter 17 – Funk and Disco - McGraw
Intelligent Information Retrieval and Web Search
No Slide Title
Tools for Historical corpus research, and a corpus of Latin
EECS 595 / LING 541 / SI 661 Natural Language Processing
Shallow semantic parsing: Making most of limited trainig data
Corpus Linguistics and ESP
Document
BOM Meta-data