☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Introduction to Programming Languages and Compilers
ISyE 8803D Formal Methods in Operations Engineering
Orientation-Spring 2015 January 6
00 Introduction - Calvin College
Essential Computer Concepts - MCST-CS
CTIS455Software Engineering
(to or for) me
Chapter 1
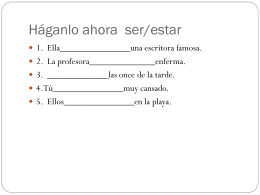
Direct and Indirect Object Pronouns
Concurrent Zero Knowledge
Flexible Transactional Storage
COS 217, Spring 2005
Indirect object pronoun ppt
PowerPoint 簡報
A Package of Parallel Algebraic Two