☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Recursividad
Practica del Tema 3 SOR
LA EMPRESA DE HOY Y EL MUNDO LABORAL
Communication & Advocacy
Diapositiva 1 - IMPULSA Puebla Tlaxcala
Hashing
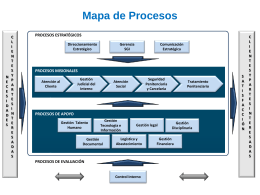
mapa de procesos inpec
Organiza tu Discurso - Bienvenidos a Toastmasters
Diapositiva 1
Tablas HASH
hash
Hashing (¿Dispersión?)