☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
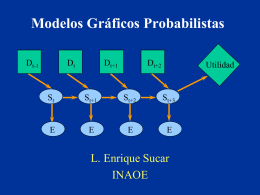
Razonamiento con Incertidumbre
PP - INAOE
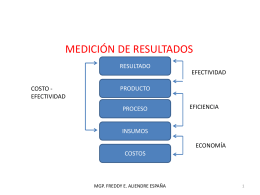
resultados
Preparación de la comida
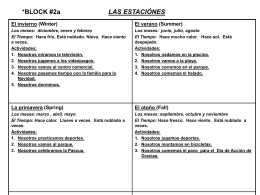
El Reporte Del Tiempo
Document
pgm-04
PRIMERO: HAZ UNA LLUVIA DE IDEAS
pgm-06
Diapositiva 1
Slide 1
pgm-resumen