☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
SIMS 290-2: Applied Natural Language Processing: …
Here is the powerpoint about the Jaguar Rescue Center in Puerto
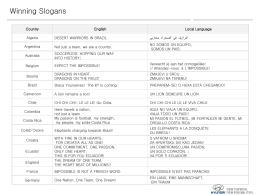
Winning Slogans Country English Local Language Algeria DESERT
VD101S3-IR
SPN II Jan 27 - Home - Gregory
Using TraceLab to Evaluate the Impact of Local versus
Term Informativeness for Named Entity Detection
BENEFITS OF YOGA
Periodic review of animal species included in the CITES Appendices
File - Jaguar Landrover - Tri
Lecture 10 Creating and Maintaining Geographic Databases
Weka Overview - University of Arizona
What is TRIO and How Can TRIO
- iBrarian.net
Basics of Consumer Protection Law
**To bring - EUSES Consortium
P1641 & XML
Chapter 11 - Lecture Notes
Best Universities & Schools
A General Optimization Framework for Smoothing …
Internet Physical Layout
\input /u/ullman/doc/nmacs - University of California
mm.sookmyung.ac.kr