☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Diapositiva 1
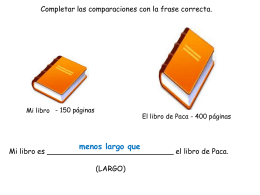
Las Comparaciones paginas 261-265
Slide 1
Tema 6. Diseños experimentales multigrupo
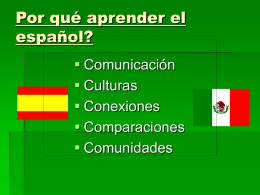
Por qué aprender el español?
actitud-positiva
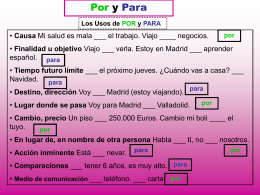
LAS COMPARACIONES
ACTITUD POSITIVA
tanto dinero como
Comunicación de Riesgos
Serie: Paseos de Eugenio Herrera