☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Presentation - Svetlin Nakov
Slide 1
Making Portable Document Format (PDF) Files Work for …
OCR GCSE Modern Foreign Languages 'Improving GCSE …
Skill up lesson - What`s the conclusion - Student sheets (PPT
Slide 1
Culture & Lifestyles
Culture & Lifestyles
Document
Introduciendo una nueva forma de hacer
Modelos Econométricos para La ONCE
Maná
Remaining Challenges talk - Carnegie Mellon University
la convivencia inteligente de sus ciudadanos
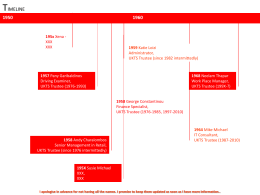
Timeline of the UKTS - United Kingdom Thalassaemia Society