☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
HMM - Tel
Introduction au « taoïsme »
Appréhender la nature des mouvements
Diapositive 1
Les différentes étapes d`une recherche
Rédaction d’articles scientifiques
*Que Horrible!
Diapositive 1
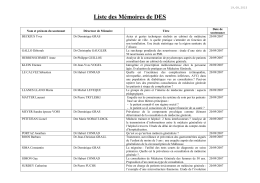
Liste des mémoires de DES de Médecine Générale
bruissement n. m. brussement n. m. bruisser v. intr. brussenaie v. intr