☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Diapositiva 1
Descarga
Document
Demostración geométrica de binomio al cuadrado (792226)
Competencia: Entiende en qué consiste un experimento y anticipa
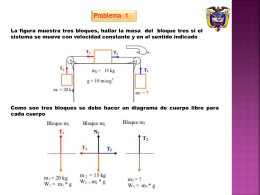
PROBLEMAS
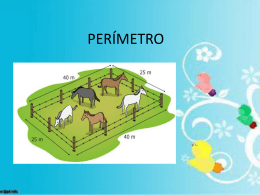
PERÍMETRO y AREA
Tarea del fin de semana Para entregar el 12 de
producto de la suma por la diferencia de dos cantidades
algebra 12 productos notables