☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Internet
Instalación y Administración de Servicios Web
INSTITUTO DE CIENCIAS Y ESTUDIOS SUPERIORES DE
No Slide Title
Power point - I like the idea
No Slide Title
Diapositiva 1 - equipobarichara
Que es Google Chrome
Diapositiva 1
Internet
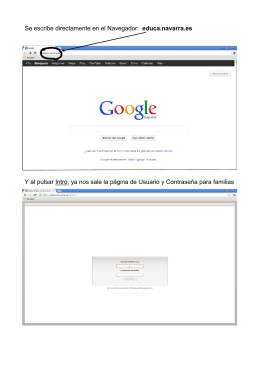
Se escribe directamente en el Navegador: educa.navarra.es Y al