☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Funciones de Varias Variables
PSF Sesión 5 parte 2
ESF 03 12 - WordPress.com
Ingeniería del trabajo
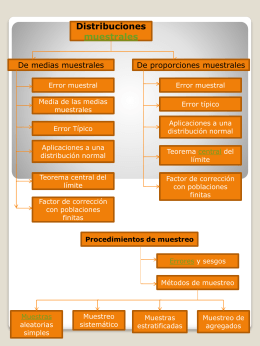
Muestra y población
Tensión entre las expectativas realistas y optimistas en los distintos
estimación del tamaño de la muestra
Diseño de Investigación
error muestral - WilliamTeneda
Población y muestra