☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Turismo
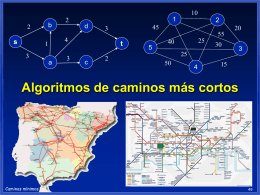
Diapositivas-Experimentacion
Características de los algoritmos
Análisis de redes.
heuristica - informationsupport
EjemplosCiclos
ALGORITMO FLOYD WARSHALL
Descargar - Fredys Simanca
Método Modificado de distribución (MODI)
Algoritmo Dijkstra
Resolución de problemas
EjemplosCiclos