☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Internet
Diapositiva 1 - vicentesanchezsri
REGIÓN DE CUYO - distritoescolar21
Consejos para la evaluación de recursos-e
SOLUCION QUE SE LE HA DADO AL SILENCIO ADMINISTRATIVO
Definición en HTML
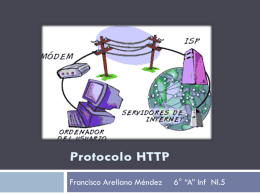
Protocolo HTTP
DERECHO DE PETICION
Fallas de Restricción de Acceso a URL
3. Manejo adecuado del tiempo
Descarga - Cl@se de T3cNoLoG!
Ejemplos de Páginas Web