☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
Presentación de PowerPoint - Contacto: 55-52-17-49-12
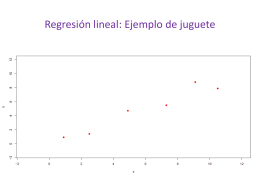
A.4 REGRESION LINEAL SIMPLE
3. Estadistica descriptiva
Precisión de las medidas y tratamiento de resultados
Clase teórica de regresión
RELACIÓN ENTRE DOS O MÁS VARIABLES
Regresión.
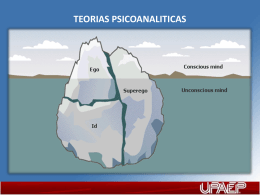
Teoría Psicoanalítica
Regresión
Modelo de Regresión Simple
ANÁLISIS DE MODELOS DE REGRESION LINEAL