☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
Ingeniería
PPT
Sistemas Distribuidos
Sistemas Distribuidos
PEÑAS NEGRAS
valor actual neto
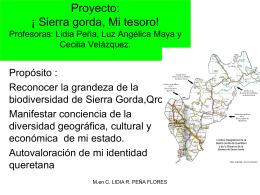
Proyec SIERRA GORDA
LA MAESTRA THOMPSON - estrategiasespecificasV
EL AGUA VIVA - iglesia evangelica rehobot
OD4
Clasificación de las industrias
INTRODUCCIÓN AL VOLEIBOL
¿Ciencia vs Religión?
Resumen Ley Federal del Trabajo Propuesta CT y SE