☰
Explorar
Iniciar sesión
Crear una nueva cuenta
Pubblicare
×
Descargar
No category
dm fl controlador difuso szc - Extraccion de Conocimiento KDD
Variables Linguisticas
Document
Conjuntos difusos - Departamento de Sistemas e Informática
Razonamiento aproximado
Que es la Minería? Para que sirve la Minería?
Minería ilegal
LA LUZ EN LA FOTOGRAFÍA
UNIVERSIDAD ALAS PERUANA ESCUELA
Cortarás el cordón umbilical - Iglesia Evangelica Bautista de Flores
Presentación de PowerPoint - Honorable Senado de la Nación
EjemplosCiclos
genética: la herencia de los caracteres
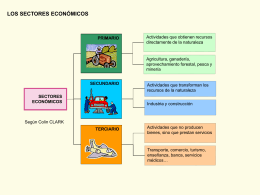
Sectores Económicos
ANÁLISIS ESTADÍSTICO DE TEXTOS Mónica Bécue Universitat